Reproducible High Dimensional Data Analysis: Is Your Lab Ready?
The foundation of the scientific method is the ability of any researcher in the scientific community to reproduce published result to strengthen the evidence or use it to advance specific knowledge.
Unfortunately, results in biomedical research often cannot be reproduced, resulting in a waste of resources and time as well as credibility. Science faces a “reproducibility crisis.” According to a survey conducted by the prestigious scientific journal Nature, over 70 percent of biology researchers say they can’t reproduce the findings of other biologists. What’s more, nearly 60 percent of those surveyed say they can’t reproduce their own results.Data and data analysis are the seeds of the “reproducibility crisis.”
High dimensionality techniques like flow cytometry, which measures the characteristics of cells and particles in a sample, empowers researchers to peer into the depths of the cell.Due to its nature, it also generates innumerable data points.
A recent Beckman Coulter Life Sciences survey revealed that over 40 percent of those working in flow cytometry consider “inconsistency from manual gating” as a primary concern related to data reproducibility in flow cytometry research.
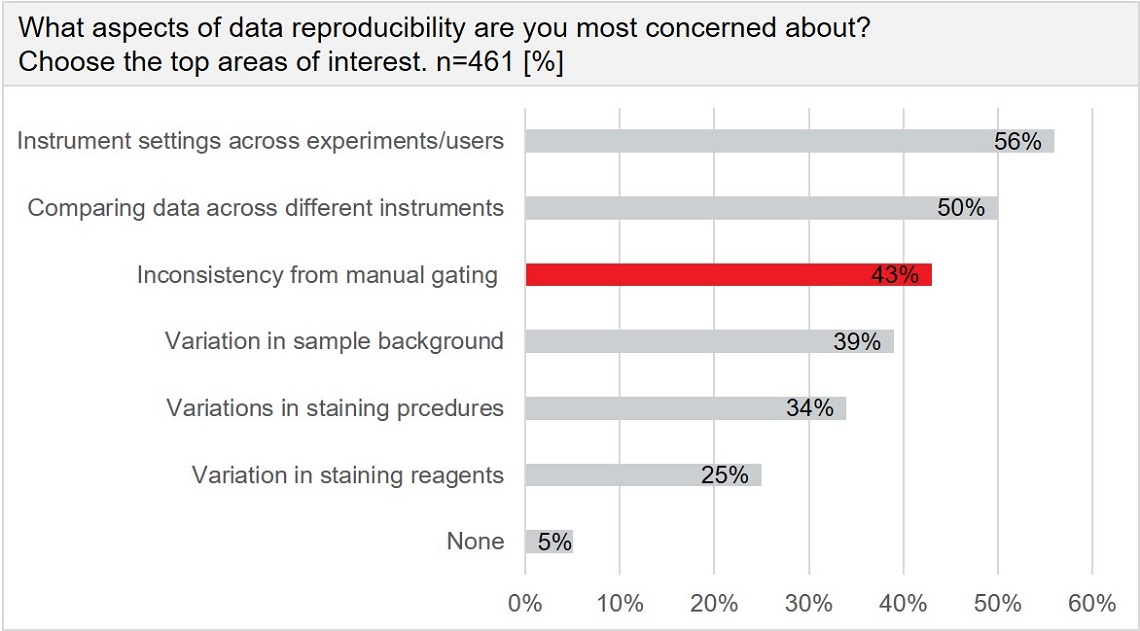
Results from 461 respondents in the field of cytometry are shown. More than 40% of users see a major weakness in inconsistencies due to manual gating.
The combination of immunology and cytometry has led to outstanding milestone discoveries in the last decades. Cytometry is a suitable solution to understand immune responses to biologic therapies. This type of research generates huge data sets, usually developed at multiple sites, for many patients and over many years.
When it comes to standardization in flow cytometry, reproducibility and data analysis are among the biggest challenges in multicolor experiments.
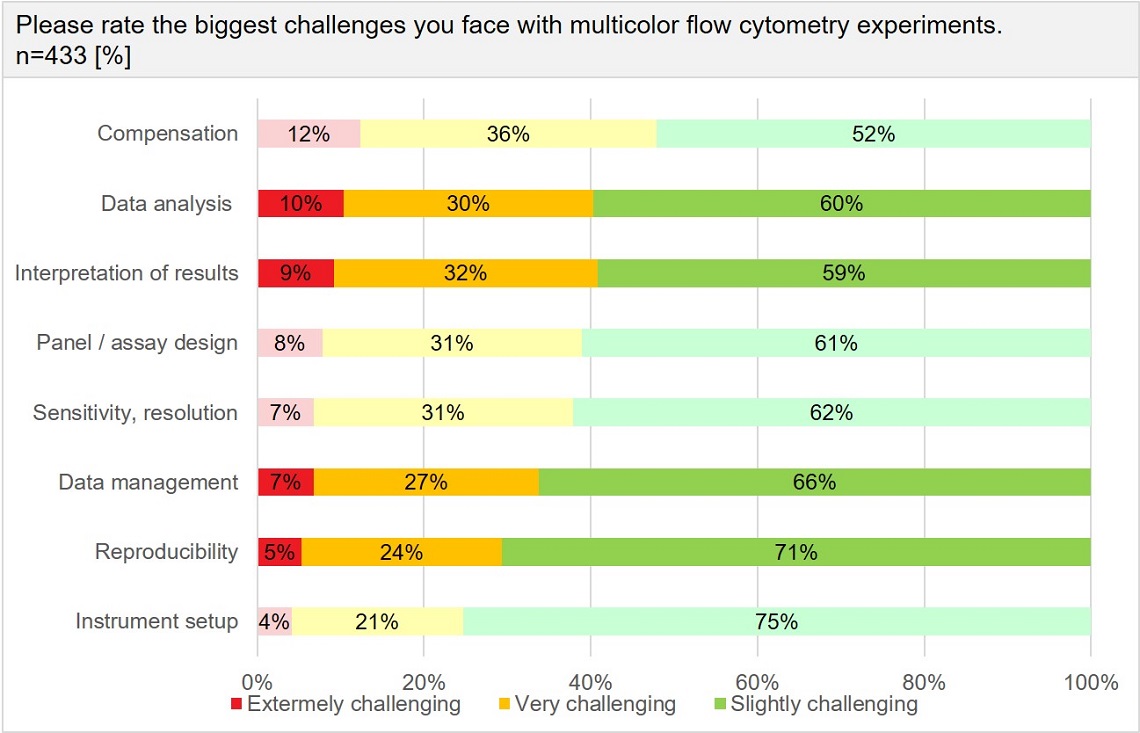
Figure 2: Result from a 2019 survey conducted by Beckman Coulter Life
Sciences
Results from 433 respondents in the field of cytometry are shown. Users rank among the greatest challenges with multicolor flow cytometry many aspects related to data analysis, management and interpretation of data.
This experimental design imposes key challenges, the most important one being the inability to manage complex data sets: many researchers do not have the knowledge or tools needed to properly analyze, interpret and store data; ultimately leading to a lack of reproducibility in studies.
Reproducible results are key to succeed in any research project and should be a requirement for all research publications. In order to achieve reproducibility, rigor needs to be applied to each step of a flow cytometry workflow: study design,
sample preparation, data acquisition and data analysis.
To design a meaningful experiment, you need to come up with a specific question with a set of possible answers to be tested. This is fundamental to successfully conducting a research project and obtain valid insights.
To ensure high quality flow cytometry the following must be taken into account:
- Correct panel design (data spread, panel/channel mismatch, viability markers)
- Quality checks with proper controls (unstained, single positive...)
- Ensuring of instrument performance (instrument QC)
- Rigorous verification of instrument settings (populations on scale, optimize threshold, stability of signal across time)
- Dimensionality of the experiment (how many events? How many samples do I need to have statistical significance?)
- Necessity for data clean up (correct for fluidics instability, gate out unwanted events)
- Correct check of spectral unmixing and compensation
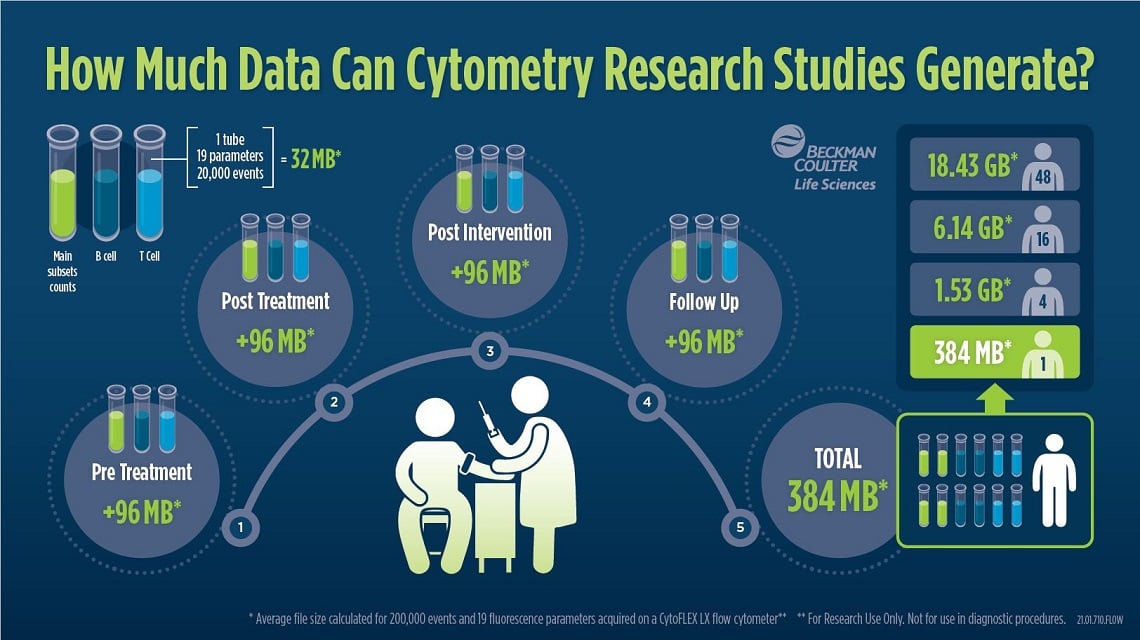
Figure 3: Infographic showing how much data can be generated in cytometry research
studies.
Example of the storage space that is needed if 3 tubes of 19 parameters each are collected for each patient at 4 time points. The FCS files of one patient have an average size of about 384 MB with the given parameters
and added to this are meta data such as patient ID, experiment number or outcome.
Indeed, data analysis is often considered as the last thing to think about. Nevertheless, rigorous data analysis is essential to ensure reproducibility of results, especially when longitudinal studies are involved.
Manual gating poses a problem because it’s dependent on humans. It introduces the potential for bias, which in turn can limit data analysis. This is where machine-learning assisted analysis comes in: utilizing algorithms for dimensionality reduction as well as for clustering reduces human error and ensures the ability to evaluate the entire population present in your samples while ensuring a level of reproducibility that manual gating cannot guarantee due to inter-operator variability. Indeed, machine learning assisted analysis of high dimensional cytometry data can help researchers with the two main settings their research might be in: a guided analysis based on prior knowledge on the population of interest or unbiased discoveries where the aim is to find all the possible cell subsets present in a given sample.
It is Important to think about how you will analyze your data when planning your research. For example, if you are testing a group of responders and a group of non- responders to a particular treatment. You can use CITRUS to identify biomarkers
present in the samples (e.g: peripheral blood) that can tell you to which group a new sample can be assigned. To use CITRUS effectively you need at least 8 files per condition. Furthermore, if you are looking for a rare population to be present
in your samples, you need to estimate how many events per sample you need to acquire to be sure you don’t miss your target population. And more, when thinking about data clean up steps, consider whether you want to include a viability
dye in your staining panels and whether you want to use a specific algorithm to identify outliers due to fluctuation in flow. Therefore, data analytics considerations can in turn inform more upstream choices in experimental design, e.g., panel
design.
Another key step to ensure reproducibility, is to be able to trace each step of data analysis: having a solution in place that automatically saves and records every run of your algorithms or every manipulation you make at your data
is critical to minimize errors and be able to inspect your results.
A platform that stores raw files and results interconnected will help to organically organize data while granting the possibility to modify any step of the analysis process, preventing errors and data loss. Furthermore, it will allow
researchers to quickly process requests from reviewers and shorten the time to publication.
Does all of this sound familiar to you? Get in touch with one of our experts and learn how the Cytobank platform can help you tackle these challenges.